The Human Ear
The human ear is an exceedingly complex organ. To make matters even more difficult, the information from two ears is combined in a perplexing neural network, the human brain. Keep in mind that the following is only a brief overview; there are many subtle effects and poorly understood phenomena related to human hearing.
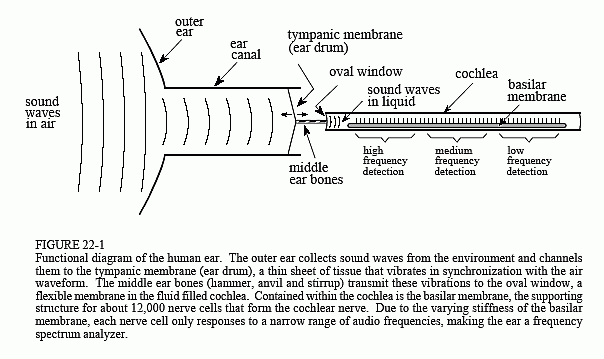
The figure illustrates the major structures and processes that comprise the human ear. The outer ear is composed of two parts, the visible flap of skin and cartilage attached to the side of the head, and the ear canal, a tube about 0.5 cm in diameter extending about 3 cm into the head. These structures direct environmental sounds to the sensitive middle and inner ear organs located safely inside of the skull bones. Stretched across the end of the ear canal is a thin sheet of tissue called the tympanic membrane or ear drum. Sound waves striking the tympanic membrane cause it to vibrate. The middle ear is a set of small bones that transfer this vibration to the cochlea (inner ear) where it is converted to neural impulses. The cochlea is a liquid filled tube roughly 2 mm in diameter and 3 cm in length. Although shown straight in Fig. 22-1, the cochlea is curled up and looks like a small snail shell. In fact, cochlea is derived from the Greek word for snail.
When a sound wave tries to pass from air into liquid, only a small fraction of the sound is transmitted through the interface, while the remainder of the energy is reflected. This is because air has a low mechanical impedance (low acoustic pressure and high particle velocity resulting from low density and high compressibility), while liquid has a high mechanical impedance. In less technical terms, it requires more effort to wave your hand in water than it does to wave it in air. This difference in mechanical impedance results in most of the sound being reflected at an air/liquid interface.
The middle ear is an impedance matching network that increases the fraction of sound energy entering the liquid of the inner ear. For example, fish do not have an ear drum or middle ear, because they have no need to hear in air. Most of the impedance conversion results from the difference in area between the ear drum (receiving sound from the air) and the oval window (transmitting sound into the liquid, see Fig. 22-1). The ear drum has an area of about 60 (mm)2, while the oval window has an area of roughly 4 (mm)2. Since pressure is equal to force divided by area, this difference in area increases the sound wave pressure by about 15 times.
Contained within the cochlea is the basilar membrane, the supporting structure for about 12,000 sensory cells forming the cochlear nerve. The basilar membrane is stiffest near the oval window, and becomes more flexible toward the opposite end, allowing it to act as a frequency spectrum analyzer. When exposed to a high frequency signal, the basilar membrane resonates where it is stiff, resulting in the excitation of nerve cells close to the oval window. Likewise, low frequency sounds excite nerve cells at the far end of the basilar membrane. This makes specific fibers in the cochlear nerve respond to specific frequencies. This organization is called the place principle, and is preserved throughout the auditory pathway into the brain.
Another information encoding scheme is also used in human hearing, called the volley principle. Nerve cells transmit information by generating brief electrical pulses called action potentials. A nerve cell on the basilar membrane can encode audio information by producing an action potential in response to each cycle of the vibration. For example, a 200 hertz sound wave can be represented by a neuron producing 200 action potentials per second. However, this only works at frequencies below about 500 hertz, the maximum rate that neurons can produce action potentials. The human ear overcomes this problem by allowing several nerve cells to take turns performing this single task. For example, a 3000 hertz tone might be represented by ten nerve cells alternately firing at 300 times per second. This extends the range of the volley principle to about 4 kHz, above which the place principle is exclusively used.
The table shows the relationship between sound intensity and perceived loudness. It is common to express sound intensity on a logarithmic scale, called decibel SPL (Sound Power Level). On this scale, 0 dB SPL is a sound wave power of 10-16 watts/cm2, about the weakest sound detectable by the human ear. Normal speech is at about 60 dB SPL, while painful damage to the ear occurs at about 140 dB SPL.
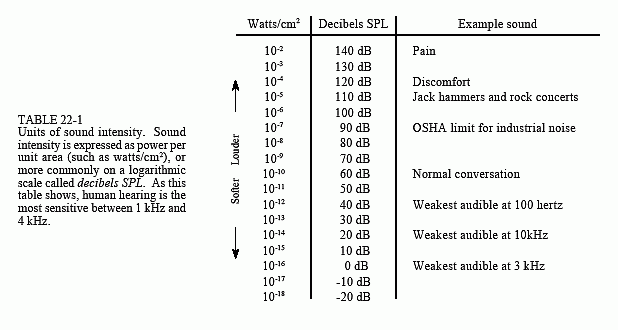
The difference between the loudest and faintest sounds that humans can hear is about 120 dB, a range of one-million in amplitude. Listeners can detect a change in loudness when the signal is altered by about 1 dB (a 12% change in amplitude). In other words, there are only about 120 levels of loudness that can be perceived from the faintest whisper to the loudest thunder. The sensitivity of the ear is amazing; when listening to very weak sounds, the ear drum vibrates less than the diameter of a single molecule!
The perception of loudness relates roughly to the sound power to an exponent of 1/3. For example, if you increase the sound power by a factor of ten, listeners will report that the loudness has increased by a factor of about two (101/3 ≈ 2). This is a major problem for eliminating undesirable environmental sounds, for instance, the beefed-up stereo in the next door apartment. Suppose you diligently cover 99% of your wall with a perfect soundproof material, missing only 1% of the surface area due to doors, corners, vents, etc. Even though the sound power has been reduced to only 1% of its former value, the perceived loudness has only dropped to about 0.011/3 ≈ 0.2, or 20%.
The range of human hearing is generally considered to be 20 Hz to 20 kHz, but it is far more sensitive to sounds between 1 kHz and 4 kHz. For example, listeners can detect sounds as low as 0 dB SPL at 3 kHz, but require 40 dB SPL at 100 hertz (an amplitude increase of 100). Listeners can tell that two tones are different if their frequencies differ by more than about 0.3% at 3 kHz. This increases to 3% at 100 hertz. For comparison, adjacent keys on a piano differ by about 6% in frequency.
The primary advantage of having two ears is the ability to identify the direction of the sound. Human listeners can detect the difference between two sound sources that are placed as little as three degrees apart, about the width of a person at 10 meters. This directional information is obtained in two separate ways. First, frequencies above about 1 kHz are strongly shadowed by the head. In other words, the ear nearest the sound receives a stronger signal than the ear on the opposite side of the head. The second clue to directionality is that the ear on the far side of the head hears the sound slightly later than the near ear, due to its greater distance from the source. Based on a typical head size (about 22 cm) and the speed of sound (about 340 meters per second), an angular discrimination of three degrees requires a timing precision of about 30 microseconds. Since this timing requires the volley principle, this clue to directionality is predominately used for sounds less than about 1 kHz.
Both these sources of directional information are greatly aided by the ability to turn the head and observe the change in the signals. An interesting sensation occurs when a listener is presented with exactly the same sounds to both ears, such as listening to monaural sound through headphones. The brain concludes that the sound is coming from the center of the listener's head!
While human hearing can determine the direction a sound is from, it does poorly in identifying the distance to the sound source. This is because there are few clues available in a sound wave that can provide this information. Human hearing weakly perceives that high frequency sounds are nearby, while low frequency sounds are distant. This is because sound waves dissipate their higher frequencies as they propagate long distances. Echo content is another weak clue to distance, providing a perception of the room size. For example, sounds in a large auditorium will contain echoes at about 100 millisecond intervals, while 10 milliseconds is typical for a small office. Some species have solved this ranging problem by using active sonar. For example, bats and dolphins produce clicks and squeaks that reflect from nearby objects. By measuring the interval between transmission and echo, these animals can locate objects with about 1 cm resolution. Experiments have shown that some humans, particularly the blind, can also use active echo localization to a small extent.
Subjective vs. Objective Sound Levels
SPL is an objective measurement of sound pressure, or power in watts, and is independent of frequency. In 1933 Fletcher and Munson of Bell Labs did a study that showed that subjective sound levels varied significantly from the SPL level. That is, when two tones were played at the exactly the same SPL level, one sounded louder than the other. And the results were very dependent on how loud the tones were to begin with. The vertical axis is the objective SPL sound level. Each of the curves in the graph represents a constant subjective sound level, which are in units called "phones." The lowest curve is the minimum audible level of sound. As noted above, the ear is most sensitive around 2-5 kHz. To be audible at this minimum level, a sound at 20Hz must be 80 dB (100 million times!) more powerful than a sound at 3 kHz.
Near the top, the curve at 100 phones is a fairly loud level. To sound equally loud at this level the sound at 20 Hz must be about 40 dB more powerful. This change in subjective level for different loudness levels means that music played softly will seem to be lacking in bass. For years pre-amps have come equipped with "loudness" controls to compensate for this. For me, part of "Hi-fidelity" means playing music at the same level it was originally played, so this is all academic - but interesting none the less.
Distortion is a commonly accepted criterion for evaluating high-fidelity sound equipment. It is usually understood to mean the tones in the reproduced sound that were not present in the original sound. An ideal sound system component has a perfectly linear response. This means that the ratio of the output and the input signal magnitude is always exactly the same, and the relative phase is constant, regardless of the strength of the signal. For a non-linear response (anything other than a linear response), distortion will occur. It is commonly categorized as total harmonic distortion (THD) and intermodulation distortion. Harmonic distortion means that a pure 1000 Hz input tone results in spurious outputs at 2000 Hz, 3000 Hz, and other integer multiples of the input frequency. Intermodulation distortion means two input tones at 1000 Hz and 100 Hz result in spurious outputs at 900 Hz, and 1100 Hz, among others.
The audibility of phase distortion is controversial. Some loudspeaker manufacturers, such as Dunlavy (apparently now out of business), cite flat phase response as a significant feature of their products.
So called "Doppler" distortion is produced by the motion of the loudspeaker cone itself. This creates some harmonic distortion, but the most significant effect is intermodulation distortion. This class of distortion can only be reduced by reducing the cone motion. A large surface, such as the membrane of an electrostatic speaker, will produce very little Doppler distortion. See the analysis for a piston in a tube for technical details.
Everest quotes research indicating that amplitude distortion has to reach a level of 3% to be audible. However this varies greatly depending on the distortion harmonic products, and on the sound source. More on this below. Good CD players, amplifiers and pre-amplifiers typically have distortion levels of 0.1% or less. (Tube amps typically have higher distortion). Loudspeakers are the weak link regarding distortion. It is hard to even get information on loudspeaker distortion since it looks embarrassing compared to the values advertised for electronics. I measured 2nd and 3rd harmonic distortion of my sound system end-to-end using my CLIO sound measuring system. Since speaker distortion dominates, this is essentially a measurement of speaker distortion. The measurement was made using one speaker; with two speakers the distortion would be the same, but the SPL levels would increase 6 dB for the two lower frequency bands, and 3 dB for the upper bands. The entire measured distortion curve at the higher power level is shown in the section on final system measurements
Psychoacoustics
Psychoacoustics is the study of subjective human perception of sounds. Alternatively it can be described as the study of the psycological correlates of the physical parameters of acoustics .
The term psychoacoustics describes the characteristics of the human auditory system on which modern audio coding technology is based. The most important psychoacoustics fact is the masking effect of spectral sound elements in an audio signal like tones and noise. For every tone in the audio signal a masking threshold can be calculated. If another tone lies below this masking threshold, it will be masked by the louder tone and remains inaudible too
The psychoacoustic model provides for high quality lossy signal compression by describing which parts of a given digital audio signal can be removed (or aggressively compressed) safely - that is, without significant losses in the (consciously) perceived quality of the sound
It can explain how a sharp clap of the hands might seem painfully loud in a quiet library, but is hardly noticeable after a car backfires on a busy, urban street. This provides great benefit to the overall compression ratio, and psychoacoustic analysis routinely leads to compressed music files that are 1/10 to 1/12 the size of high quality masters with very little discernible loss in quality. Such compression is a feature of nearly all modern audio compression formats. Some of these formats include MP3, Ogg Vorbis, AAC, WMA, MPEG-1 Layer II (used for digital audio broadcasting in several countries) and ATRAC, the compression used in MiniDisc and some Walkman models
Psychoacoustics is based heavily on human anatomy, especially the ear's limitations in perceiving sound as outlined previously. To summarize, these limitations are:
-High frequency limit
-Absolute threshold of hearing
-Temporal masking
-Simultaneous masking
-Music
Given that the ear will not be at peak perceptive capacity when dealing with these limitations, a compression algorithm can assign a lower priority to sounds outside the range of human hearing. By carefully shifting bits away from the unimportant components and toward the important ones, the algorithm ensures that the sounds a listener is most likely to perceive are of the highest quality
In Music Psychoacoustics includes topics and studies which are relevant to music psychology and music therapy. Theorists such as Benjamin Boretz consider some of the results of psychoacoustics to be meaningful only in a musical context.
Psychoacoustics ModelPsychoacoustics is presently applied within many fields from software development, where developers map proven and experimental mathematical patterns; in digital signal processing, where many audio compression codecs such as MP3 use a psychoacoustic model to increase compression ratios; in the design of (high end) audio systems for accurate reproduction of music in theatres and homes; as well as defense systems where scientists have experimented with limited success in creating new acoustic weapons, which emit frequencies that may impair, harm, or kill. It is also applied today within music, where musicians and artists continue to create new auditory experiences by masking unwanted frequencies of instruments, causing other frequencies to be enhanced. Yet another application is in design of small or lower-quality loudspeakers, which use the phenomenon of missing fundamentals to give the effect of low frequency bass notes that the system, due to frequency limitations, cannot actually reproduce.

Human hearing is a superior defensive system.
The human ear is a truly remarkable instrument. Electronic Counter Measures (ECM) systems for the U. S. military. The primary function of an ECM system is to detect an enemy before he (it's rarely a she) detects you, for self-defense.
Human hearing is a superior defensive system in every respect except source location accuracy..
In contrast, a military system designed for communications (rather than detection) would typically have a much smaller ratio of highest-to-lowest frequency, no source location capability, and often a narrow directional coverage. For human communication a frequency ratio of 10:1 and a ratio of strongest to weakest signal of 10,000:1 would suffice. The far larger actual ratios strongly imply a purpose other than communication.
All of this tells me that the ear evolved primarily for self-defense (or perhaps hunting, as one reader pointed out), and language and enjoyment of music are delightful evolutionary by-products. A defensive purpose also suggests some direct hard-wiring between the ears and primitive parts of the brain, which may account for the powerful emotional impact of music - and its virtual universality among human cultures.
{kind=link}

Lenny Z. Perez M
EES
Referencias:
http://www.silcom.com/~aludwig/EARS.htm
http://www.dspguide.com/ch22/1.htm
http://en.wikipedia.org/wiki/Psychoacoustics
Discover the new Windows Vista Learn more!
Get news, entertainment and everything you care about at Live.com. Check it out!
No hay comentarios:
Publicar un comentario